
Постановка задачи. В современном быстро меняющемся мире у нас есть только 24 часа в сутки, чтобы понять и усвоить всю информацию, которую мы собираем. Давайте сделаем паузу и предположим, сколько писем отправляется каждый день… 1 миллион?… 2 миллиона? нет, колоссальные 124,5 миллиарда электронных писем отправляются каждый день. На индивидуальном уровне средний офисный работник получает 121 электронное письмо в день. Когда вы размазаны, никто не любит читать электронную почту. Как легко было бы, если бы вы получили обобщенный набор ключевых слов и быструю визуализацию, которая сэкономила бы массу времени и избавила бы вас от хлопот, связанных с чтением всего.
Решение. Я представляю простое решение для извлечения ключевых слов с помощью алгоритма Быстрое автоматическое извлечение ключевых слов в Python.
Что нужно сделать
- Установка RAKE в Python: pip install python -rake==1.4.4 или https://pypi.org/project/python-rake/#files
- Стоп-слова. Это слова, которые программисты ненавидят, а писатели любят. *прямое лицо. Это слова-связки, которые делают английское предложение осмысленным (например, An, Always, Anything и т. д.). Список стоп-слов для RAKE можно скачать ЗДЕСЬ. Этот список необходим для настройки RAKE для удаления этих стоп-слов из текста.
- Реализация Python
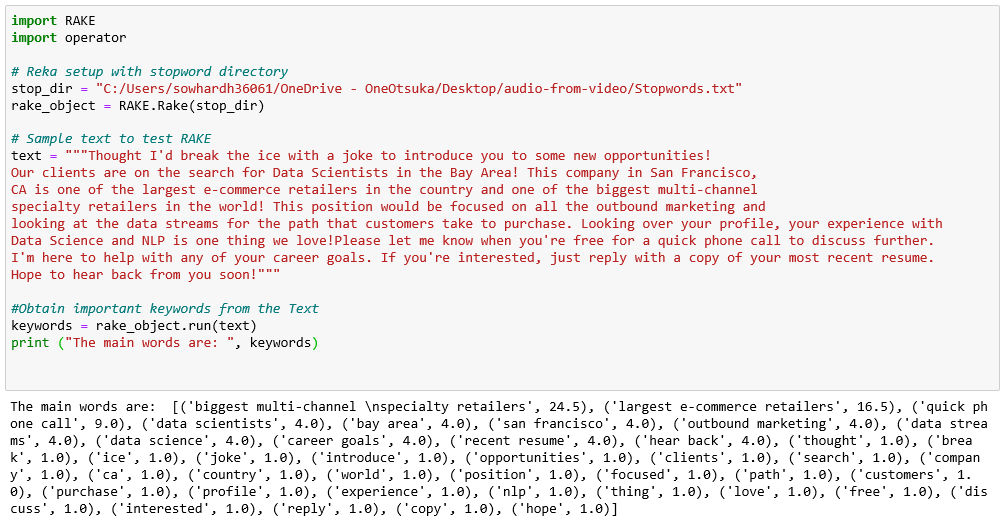

Извлечение верхних 25 процентилей ключевых слов дает нам следующие слова:
[('крупнейшие многоканальные\nспециализированные розничные продавцы', 24,5), ('крупнейшие розничные интернет-магазины', 16,5), ('быстрый телефонный звонок', 9.0), ('специалисты по данным', 4.0), ('залив', 4.0), ('сан-франциско', 4.0), ('исходящий маркетинг', 4.0), ('потоки данных', 4.0), ('наука о данных' , 4,0), ('карьерные цели', 4,0), ('недавнее резюме', 4,0), ('услышать ответ', 4,0 )
Глядя на приведенное выше представление, я могу легко понять, что электронное письмо "О вакансии в розничной компании в Сан-Франциско, мне нужно мое недавнее резюме и я хочу быстро позвонить по телефону".
Логика алгоритма RAKE
Шаг 1: переводит все слова в нижний регистр (пример: - Sowhardh, What are you to→ sowhardh, what you upto)
Шаг 2: текст разбивается на массив отдельных слов, которые можно указать с помощью разделителей, таких как « , », « . " и т.д.
Привет, что ты делаешь →
[‘sowhardh’,
‘что’,
‘есть’,
‘ты’,
‘до’]
Шаг 3: стоп-слова удаляются, а слова, идущие по порядку, назначаются на ту же позицию. В приведенном выше примере результатом будет: sowhardh upto как одно слово-кандидат.
Этап 4. Оценка ключевого слова рассчитывается с помощью графика совпадений с использованием отношения Степени слов к Частоте слов.
Давайте подробно разберемся с расчетом оценки ключевого слова.
Какова Частота слов?
Рассмотрим предложение -› «Чикаго — лучший город в мире. Глубокие блюда Чикагопиццылучше, чем в Италии → Частота (Чикаго) = 2
После 2 шагов RAKE приведенное выше предложение будет выглядеть так:
['Чикаго',
'город',
'мир',
'Чикагская пицца с глубоким блюдом',
'Италия']
Что такое степень слов?
Степень Чикаго = (5)
Количество раз, когда мир появляется отдельно + количество раз, когда он
появляется вместе с составным словом.
1. Чикаго (первое ключевое слово)
2. Чикаго (ключевое слово в 4-м составном слове)
3. deep Chicago
4. блюдо Чикаго
5. Чикагская пицца
Вот как мы приходим к степени (Чикаго) = 5
Оценка ключевого слова для Чикаго = Степень (Чикаго) / Частота (Чикаго) = 5/2 = 2,5. Другими словами, показатель RAKE низкий для высокочастотных терминов и наоборот. Он выделяет отдельные слова с высокой степенью и низкой частотой во входном тексте.
Будущая работа
RAKE имеет широкий спектр практических применений. Вышеприведенное является лишь простой иллюстрацией того, как его можно использовать. Его можно использовать в сочетании с классификатором моделирования TOPIC для классификации ключевых слов по темам, выходные данные RAKE можно использовать в SQLNet для генерации запросов SQL из этих ключевых слов RAKE, полученных с помощью естественного языка и т. д.