Если бы вы были разработчиком в течение некоторого времени, вы бы заметили, что мы работаем в отрасли, полной изменений. «Инновационные» технологии появляются каждый день. Мы постоянно слышим о новых языках программирования, фреймворках, архитектурах и шаблонах. Но есть кое-что, чем я пользуюсь давно и не претерпевал слишком радикальных изменений. Я имею в виду SQL.
Мы используем PostgreSQL для наших проектов, и я обычно использую одни и те же предложения SQL для большинства своих запросов. Но время от времени я обнаруживаю новые инструкции или типы данных, которые никогда раньше не видел, и это меня очень радует.
Одна из вещей, которую я открыл для себя несколько месяцев назад и которой не перестаю пользоваться, — это предложение DISTINCT ON. В этой статье я расскажу вам, когда и как его использовать. Давайте погрузимся и начнем!

Давайте представим, что у нас есть база данных, в которой мы храним информацию о разработчиках и коммитах, созданных этими разработчиками.
Для каждого коммита мы сохраняем его хеш и количество связанных изменений.

Отлично, у нас есть таблицы, давайте теперь создадим некоторые данные.
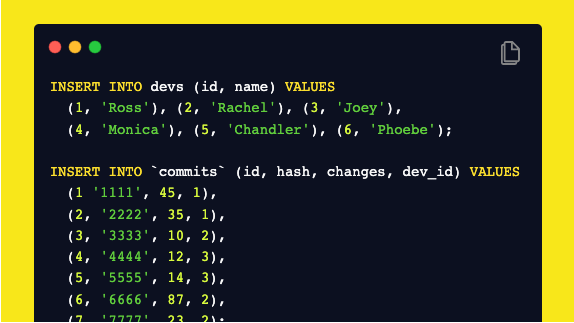
Давайте представим, что мы хотим, чтобы отчет содержал всех разработчиков и их коммит с дополнительными изменениями. Другими словами, если у Ross есть commit_1 (с 10 изменениями) и commit_2 (с 20 изменениями), он должен вернуть Ross с commit_2.
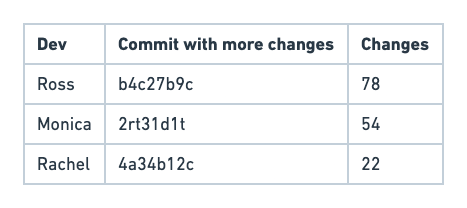
Мы могли бы создавать запросы, используя разные подходы, так что давайте посмотрим на них.
Использование ВНУТРЕННЕГО СОЕДИНЕНИЯ
Мы могли бы использовать INNER JOIN с подзапросом, который получает для каждого разработчика их коммит с большим количеством изменений:

Это решение работает хорошо, но ему действительно трудно следовать. У нас есть соединение с подзапросом, использующим функцию агрегации, которую затем мы должны пересечь с основным запросом.
Использование WHERE IN
Мы могли бы иметь подзапрос, который получает коммит с большим количеством изменений для каждого разработчика, а затем использовать IN для фильтрации коммитов.
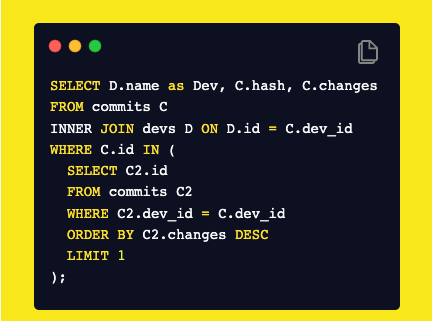
Эта версия легче для чтения и понимания. Мы используем простое INNER JOIN, а сложность перенесена в предложение WHERE.
Использование DISTINCT ON
Давайте попробуем использовать DISTINCT ON, чтобы получить этот отчет.
DISTINCT ON используется для сохранения только первой строки каждого набора строк, где данное выражение оценивается как равное (официальная документация).
Итак, используя DISTINCT ON, мы можем создать такой запрос:

Как видите, запрос стал более простым и читабельным. Вот следующие шаги:
- групповые фиксации по идентификатору dev => DISTINCT ON (dev_id)
- порядок коммитов по их изменениям =› ORDER BY dev_id, изменяет DESC
- вернуть столбцы первой строки
—
SQL — это мощный язык, и, как мы видели, мы можем использовать разные подходы к данной задаче. Мы проанализировали проблему и пошли тремя не связанными путями, чтобы прийти к одному и тому же результату.
Удобочитаемость — это то, что я ценю и принимаю каждый раз, когда пишу любой фрагмент кода, и, как мы могли видеть, последний подход более прямолинеен и понятен.
Я надеюсь, что вы нашли эту статью полезной, и я хотел бы услышать о вашем опыте.
Если вам понравилась эта статья, возможно, вас заинтересует одна из них: