Я работаю над GCC в течение некоторого времени и хотел бы поделиться некоторыми из моих экскурсий по стране GCC -;) Добавление оптимизации глазка - хорошая отправная точка, поскольку это один из самых простых способов изменить GCC, а также дает мне возможность немного рассказать о моем первом нетривиальном вкладе в GCC, который также был моим проектом GSoC 2014.
Вид на GCC с высоты 10 км
Архитектура GCC и процесс сборки заслуживают отдельного поста, это очень упрощенный обзор процесса. Грубо говоря, GCC разделен на три компонента высокого уровня - внешний интерфейс, так называемый «средний конец» и серверный компонент.
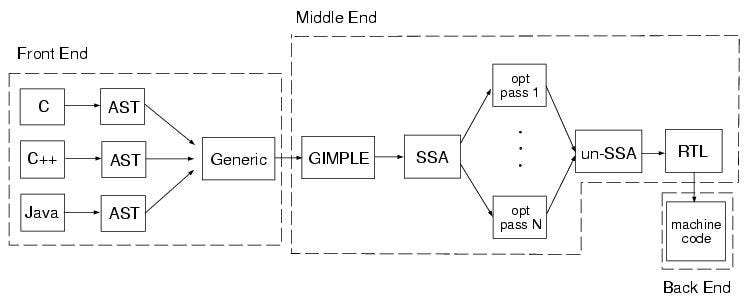
Интерфейс занимается языковыми проблемами, такими как лексический анализ и синтаксический анализ, и в итоге создает общее абстрактное синтаксическое дерево, которое на языке GCC называется GENERIC. GENERIC - это высокоуровневое промежуточное представление на основе дерева, общее для всех интерфейсов GCC.
Затем GENERIC IR понижается до другого IR более низкого уровня, называемого GIMPLE, который является версией GCC трехадресного кода. Оператор в трехадресном коде может иметь не более трех операндов. Это делает его похожим на структуру сборки, оставаясь при этом независимым от целей, что делает его подходящим для машинно-независимых оптимизаций. Чтобы проиллюстрировать это, рассмотрим следующее выражение C:
x = (a * b) + (c * d) - e;
В формате трехадресного кода это выглядело бы так:
_1 = a * b _2 = c * d _3 = _1 + _2 _4 = _3 - e x = _4
Где переменные _1, _2, _3, _4 являются временными объектами, созданными компилятором.
Следующим шагом в компиляторе является построение графа потока управления (сокращенно CFG) функции. Узел в CFG представляет собой базовый блок (последовательность прямолинейных операторов GIMPLE), а поток управления представлен в виде границ между базовыми блоками. Компилятор автоматически добавляет фиктивные блоки входа и выхода для анализа потока данных.
Затем представление понижается до формы SSA, которая является выбором IR для современных оптимизаций компилятора. Заметное отличие формы SSA от традиционного формата трехадресного кода состоит в том, что присвоение переменной разрешено только один раз. Это упрощает реализацию нескольких оптимизаций, делая цепочки use-def явными в IR, а также синглтон (поскольку есть только один def). Для получения дополнительных сведений о SSA ознакомьтесь с этими слайдами CMU.
Затем компилятор выполняет большую часть машинно-независимых оптимизаций для этой формы SSA, а затем понижает ее до третьего и последнего промежуточного представления в GCC, называемого языком передачи регистров или сокращенно RTL. RTL - это низкоуровневый IR, используемый для целевой оптимизации и генерации кода.
Оптимизация глазка
Оптимизация на глазок / сворачивание - одна из самых простых оптимизаций, сделанных в компиляторе. Одним из примеров может быть преобразование * 2 в ‹( 1, предполагая, что сдвиг влево быстрее, чем умножение, что верно для большинства процессоров. Сворачивание выражений выполняется на всех IR в компиляторе. В этом посте я в основном сосредоточусь на сворачивании на уровне GENERIC и GIMPLE.
В GCC есть надежная папка GENERIC в fold-const.c, которая работает для сворачивания одного выражения. Однако не было настоящей папки GIMPLE, которая бы сворачивала операторы на уровне базовых блоков. Чтобы проиллюстрировать эту мысль, рассмотрим это выражение:
x = (a / 2) * 2; // assume 'a' is unsigned
В GENERIC он будет представлен как одно выражение и свернут до & ~ 1.
Однако, если это явно написано в источнике в следующей форме:
t1 = a / 2; t2 = t1 * 2; x = t2
Папка GENERIC больше не сможет сворачивать ее, потому что в GENERIC они будут представлены в виде трех разных выражений. Следовательно, необходима папка на основе GIMPLE, которая может выполнять сворачивание на уровне базовых блоков.
GIMPLE разделяет некоторые внутренние структуры данных с GENERIC, в первую очередь «дерево» для представления операндов. Для удобства, когда реальной папки GIMPLE не было, операторы GIMPLE в базовом блоке были преобразованы обратно в ОБЩЕЕ представление для сворачивания, а затем снова опустились до GIMPLE! Это был и конструкторский беспорядок, и вычислительно дорогостоящий процесс компилятора. Но написать целую папку GIMPLE с нуля было огромной задачей! Кроме того, реализация двух разных версий одного и того же паттерна была некрасивой с точки зрения обслуживания.
Для решения этих проблем Ричард Байнер, плодовитый разработчик GCC, разместил в списке рассылки предложение о создании нового предметно-ориентированного языка для написания шаблонов сворачивания под названием «match.pd» и инструмента (genmatch.c), который будет читать эти шаблоны и генерируют код C, который выполняет сворачивание как для GENERIC (generic-match.c), так и для GIMPLE (gimple-match.c). Таким образом, однократная реализация шаблона позволила сделать его доступным как для IR, так и в более удобном формате. В то же время настроить таргетинг на RTL было бы намного сложнее. Мой проект GSoC под руководством Ричарда заключался в создании начальной версии genmatch.c.
В сторону - создание GCC
Прежде чем мы продолжим работу с кодом, вот краткое руководство по созданию современной версии GCC на недавнем дистрибутиве Ubuntu. Я ожидаю, что это будет похоже на другие дистрибутивы, но я до сих пор никогда не пробовал.
sudo apt install build-essentials flex bison sudo apt-get build-dep gcc mkdir gnu-toolchain cd gnu-toolchain git clone https://github.com/gcc-mirror/gcc cd gcc ./contrib/download_prerequisites # Make a *separate* build dir, which is sibling to gcc/ cd .. mkdir stage1-build cd stage1-build ../gcc/configure --enable-languages=c,c++ --disable-bootstrap --disable-multilib nohup make -j$(nproc) >err 2>&1 &
Если все пойдет хорошо, в каталоге stage1-build / gcc / должен быть исполняемый файл cc1. cc1 - это фактический двоичный файл компилятора C. Мы будем использовать его напрямую (а не драйвер) в целях тестирования.
Создание шаблона match.pd
Давайте добавим простое преобразование в gcc: sin² (x) + cos² (x) - ›1.
double f(double x)
{
return (__builtin_sin(x) * __builtin_sin(x))
+ (__builtin_cos(x) * __builtin_cos(x));
}
double g(double x)
{
double t1 = __builtin_sin (x);
double t2 = t1 * t1;
double t3 = __builtin_cos (x);
double t4 = t3 * t3;
return t2 + t4;
}
Примечание. Я просто использую вышеприведенный надуманный шаблон в качестве примера. На практике очень маловероятно, что пользователь напишет это таким образом, поэтому нет смысла реализовывать это в компиляторе.
Обоснование написания двух разных версий одного и того же тестового примера, f и g, заключается в том, что сворачивание в 'f' должно выполняться папкой GENERIC, поскольку оно будет представлено как одно выражение в GENERIC, а сворачивание в 'g' нужно будет сделать с помощью папки GIMPLE.
Давайте проверим, что шаблон еще не реализован в компиляторе. Мы можем сделать это, проверив оптимизированный дамп, сгенерированный GCC, который является окончательным результатом работы мидл-энда.
cc1 -O2 -fdump-tree-optimized-details показывает (файл с расширением .optimized):
;; Function g (g, funcdef_no=1, decl_uid=1909, cgraph_uid=2, symbol_order=1)
g (double x)
{
double t4;
double t3;
double t2;
double t1;
double _6;
complex double sincostmp_8;
<bb 2> [local count: 1073741825]:
sincostmp_8 = __builtin_cexpi (x_1(D));
t1_2 = IMAGPART_EXPR <sincostmp_8>;
t2_3 = t1_2 * t1_2;
t3_4 = REALPART_EXPR <sincostmp_8>;
t4_5 = t3_4 * t3_4;
_6 = t2_3 + t4_5;
return _6;
}
Дамп для f будет таким же. Любопытное появление __builtin_cexpi выше - это преобразование sincos, которое заменяет вызовы комбинированного вхождения sin (x) и cos (x) на вызов cexpi (x), чтобы воспользоваться преимуществом идентичности Эйлера: cexpi (x) = cos ( x) + i * sin (x) и, таким образом, вычислить sin и cos с помощью одного вызова функции. Но это не имеет отношения к нашему шаблону.
Чтобы реализовать преобразование, добавьте в match.pd следующий шаблон:
(simplify (plus (mult (SIN @0) (SIN @0)) (mult (COS @0) (COS @0))) (if (flag_unsafe_math_optimizations) { build_one_cst (TREE_TYPE (@0)); }))
Несколько замечаний по поводу вышеприведенного шаблона:
- Simpleify означает, что это шаблон, который состоит из двух частей: соответствия, условия и замены.
- совпадение: Условие совпадения - это выражение, начинающееся с (плюс…). Компилятор сопоставляет входящее выражение или операторы TREE в базовом блоке с этим шаблоном, и, если сопоставление с шаблоном выполнено успешно, он заменит это на последовательность из замещающей части.
- mult обозначает оператор умножения, записанный в нижнем регистре. Встроенные функции, такие как sin и cos, обозначаются прописными буквами.
- @ 0 - это так называемый «захват», который используется для представления операнда или «листа» выражения. В нашем случае @ 0 будет x.
- Условие (если…) - это фактическое условие C, встроенное в шаблон. Это кладж, поскольку в идеале мы хотим, чтобы определения шаблонов определялись только с помощью DSL, но переход к C становится необходимым, когда язык шаблонов недостаточно выразителен или нам нужен доступ к некоторым другим вещам, таким как flag_unsafe_math_optimizations в приведенном выше случае. Преобразование ограничено флагом, чтобы быть консервативным.
- Наконец, переходя к замене, это может быть либо конструкция языка шаблонов, заключенная в (…), либо выражение C, заключенное в фигурные скобки {…}. В приведенном выше примере в языке шаблонов нет конструкции для построения узла дерева, поэтому мы «возвращаемся» к коду C, чтобы построить узел дерева с константой 1 с помощью функции build_one_cst. Макрос TREE_TYPE возвращает тип «x», который в нашем случае является двойным, но также могут быть другими вариантами с плавающей запятой.
Во время сборки GCC инструмент genmatch.c будет читать match.pd и генерировать эквивалентный код C для GENERIC сворачивания в generic-match.c и сворачивания GIMPLE в gimple-match.c. Например, следующая функция gimple_simplify_273 - это автоматически сгенерированная функция C, реализующая «условие и замену» части вышеприведенного шаблона в gimple-match.c:
static bool
gimple_simplify_273 (gimple_match_op *res_op, gimple_seq *seq,
tree (*valueize)(tree) ATTRIBUTE_UNUSED,
const tree ARG_UNUSED (type), tree *ARG_UNUSED (captures)
, const combined_fn ARG_UNUSED (SIN), const combined_fn ARG_UNUSED (COS))
{
/* #line 5004 "../../gcc/gcc/match.pd" */
if (flag_unsafe_math_optimizations)
{
gimple_seq *lseq = seq;
if (dump_file && (dump_flags & TDF_FOLDING)) fprintf (dump_file, "Applying pattern match.pd:5005, %s:%d\n", __FILE__, __LINE__);
tree tem;
tem = build_one_cst (TREE_TYPE (captures[0]));
res_op->set_value (tem);
return true;
}
return false;
}
Часть «совпадение» объединяется с частями «совпадения» других шаблонов в форме дерева решений, чтобы избежать дублирующих проверок.
Попробуем проверить, работает ли шаблон. Чтобы проверить, выполнила ли папка GENERIC свою работу, нам нужно будет проверить дамп «gimple», то есть вывод GIMPLE, созданный «gimplifier», который понижает GENERIC до GIMPLE IR.
cc1 -O2 -funsafe-math-optimizations -fdump-tree-gimple-details показывает:
f (double x)
{
double D.1917;
D.1917 = 1.0e+0;
return D.1917;
}
Из приведенного выше дампа ясно видно, что папка GENERIC выполнила свою работу, заменив sin² (x) + cos² (x) на 1.
Для функции g мы видим, что проход разреженного условного распространения констант (сокращенно SCCP) выполнял сворачивание как часть своей операции.
cc1 -O2 -funsafe-math-optimizations -fdump-tree-ccp-details:
Visiting statement:
t5_6 = t2_3 + t4_5;
which is likely CONSTANT
Match-and-simplified t2_3 + t4_5 to 1.0e+0
Lattice value changed to CONSTANT 1.0e+0. Adding SSA edges to worklist.
marking stmt to be not simulated again
g (double x)
{
double t5;
double t4;
double t3;
double t2;
double t1;
<bb 2> :
t1_2 = __builtin_sin (x_1(D));
t2_3 = t1_2 * t1_2;
t3_4 = __builtin_cos (x_1(D));
t4_5 = t3_4 * t3_4;
return 1.0e+0;
Из приведенного выше дампа мы можем проверить, что возвращаемое значение было упрощено до 1.0. Обратите внимание, что проход SCCP выполняет свою функцию - распространяет константы, другие проходы, такие как удаление мертвого кода, будут выполнять работу по очистке вызовов sin и cos. В итоге мы видим следующий оптимизированный дамп:
g (double x)
{
<bb 2> [local count: 1073741825]:
return 1.0e+0;
}
Дополнительные сведения о синтаксисе языка шаблонов см. Во внутренней документации GCC: https://gcc.gnu.org/onlinedocs/gccint/Match-and-Simplify.html#Match-and-Simplify и на этих отличных слайдах. профессора Удая Хедкера и его команды: https://www.cse.iitb.ac.in/grc/gcc-workshop-13/. Они немного устарели, но дают хороший концептуальный обзор GCC.
Итак, это было короткое введение в GCC и match.pd. Надеюсь, вам понравилось -;)
Кредиты
Спасибо пользователю Reddit IshKebab за указание на ошибку в шаблоне раскладки_1 в ветке reddit. Теперь оно исправлено на (a / 2) * 2 -> a & ~1, если a беззнаковое.