
В этом простом примере описывается потенциальное применение анализа настроений. Моя мотивация заключалась в том, чтобы поближе познакомиться с новым iPhone 11, точнее, мне было любопытно, оцениваются его характеристики положительно или нет. Чтобы выяснить это, я провел анализ настроений по количественным обзорам iPhone 11.
Сначала я погуглил Обзор iPhone 11 и выбрал две статьи из первых 20 самых популярных результатов. Я выбрал статью, опубликованную на digitaltrends.com, и еще одну, опубликованную на wired.com. Обе статьи актуальны, но, кроме этого, выбор этих статей был случайным, учитывая, что я прочитал их только после того, как сделал свой выбор.

Во-вторых, я очистил две статьи. Я использовал расширение SelectorGadget для Google Chrome, чтобы определить соответствующую часть страницы, генерирующую селекторы CSS для моих нужд. Затем я использовал пакет rvest в R для загрузки необходимого содержимого.
Например, я использовал следующий фрагмент кода, чтобы получить статью digitaltrends.com:

Наконец, я использовал Amazon Comprehend для анализа тональности, который представляет собой службу обработки естественного языка (NLP) Amazon, которая использует машинное обучение для поиска идей и взаимосвязей в тексте. Amazon Comprehend также предлагает решения для извлечения ключевых фраз, анализа настроений, распознавания сущностей, моделирования тем и определения языка.
После входа в Консоль управления AWS я набрал Comprehend в строке поиска и выбрал Amazon Comprehend, чтобы открыть консоль сервиса.
Затем я запустил Amazon Comprehend, чтобы начать работу с самим сервисом.
Затем я выбрал вариант анализа в реальном времени в меню слева.

Я просто скопировал и вставил вычищенные тексты статей в поле и нажал кнопку «Анализ». Я решил провести анализ настроений отдельно, характеристика за характеристикой, вместо того, чтобы анализировать всю статью в целом, потому что мне было любопытно, какие функции упоминаются как хорошие, а какие как плохие. С другой стороны, есть и техническая причина, учитывая, что для каждого анализа существует ограничение в 5000 символов.
В результате на листе Sentiment я получил четыре балла (номера достоверности) для каждого текста, отражающие тональность отзывов:
- Нейтральный: уверенность (измеряемая в процентах) в том, что текст является нейтральным,
- Положительный: уверенность (измеряемая в процентах) в том, что текст является положительным,
- Отрицательный: уверенность (измеряемая в процентах) того, что текст отрицательный,
- Смешанный: достоверность (измеряемая в процентах) того, что текст является смешанным.
Получил следующие результаты (цифры округлены):
РЕЗУЛЬТАТЫ ОБЗОРОВ DIGITAL TREND

Результаты говорят о том, что, согласно обзору digital Trends, самой слабой особенностью iPhone 11 является дисплей. Это соответствует истинному содержанию текста. Если проверить ключевые фразы текста, то перечислены следующие: «самое слабое звено», «не OLED-панель». Также в статье упоминается следующее:
«Тем не менее, у iPhone 11 нет экрана, соответствующего его цене. Это отстает от конкурентов. Нет, это не плохо, но можно найти лучше по той же цене или дешевле».
Что касается остальных признаков, то отзыв воспринимается алгоритмом скорее как положительный, чем как отрицательный, что полностью соответствует истинному содержанию.
РЕЗУЛЬТАТЫ ОБЗОРОВ НА WIRED
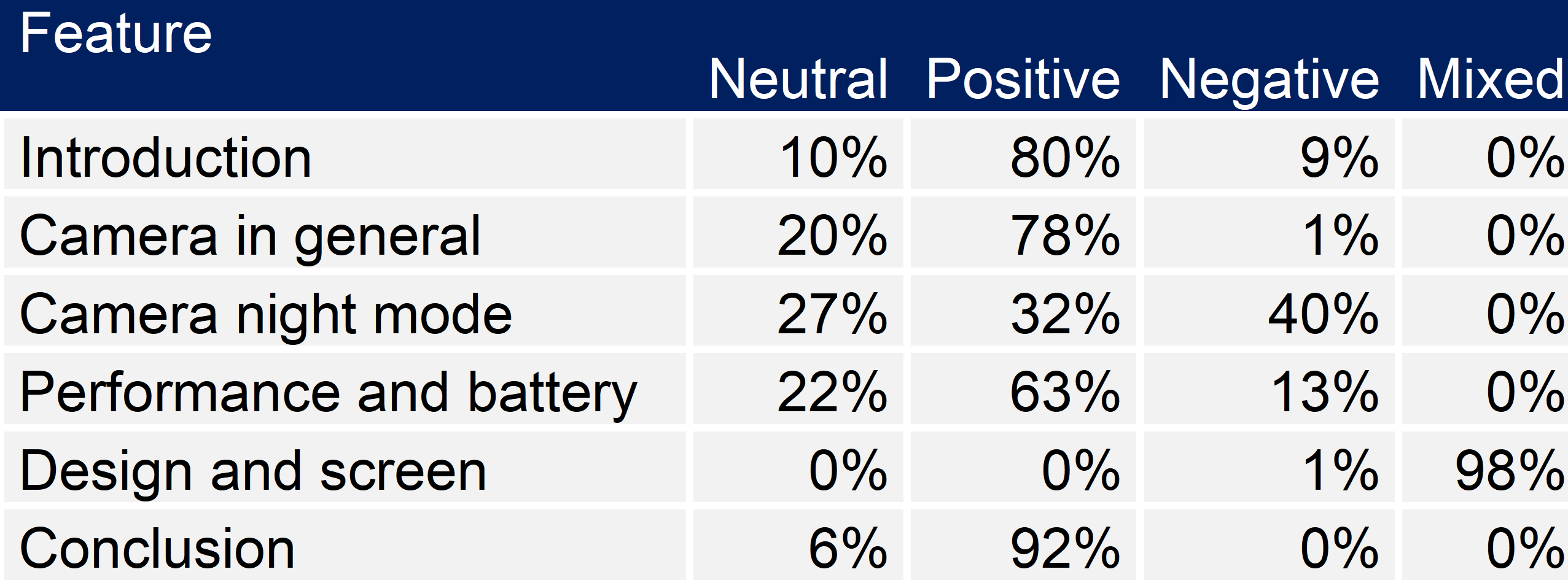
Я получил немного другие результаты после анализа чувствительности обзора на Wired. Дизайн и просмотр экрана воспринимались алгоритмом как смешанные. На мой взгляд, это не так уж далеко от истинного содержания статьи, потому что наряду с негативными комментариями (например, «Впервые часть iPhone выглядит немного некрасиво, и это не может не сказаться на уличном авторитете Apple». ) также упоминаются некоторые положительные качества (например, «кажется, что этот дисплей немного слабоват, чтобы этот дисплей застрял на 326ppi») также упоминаются, и в целом, основываясь на обзоре, трудно решить, хороший дисплей или плохой. Что касается ночного режима, который является новой функцией iPhone, то, судя по анализу настроений, отзыв скорее негативный. Что ж, читая статью, я думаю, что этот результат недействителен, а с другой стороны, я получил противоположные результаты в случае обзора Digital Trends. Вероятно, это связано с тем, что анализ чувствителен к длине текста, чем длиннее текст, тем больше шансов правильно его проанализировать. Статья о цифровых тенденциях почти в два раза длиннее, чем статья о Wired, что может быть одной из причин, по которой результаты, связанные с цифровыми тенденциями, кажутся более точными и достоверными.
В целом выводы обеих статей были оценены довольно положительно, что я нашел абсолютно верным после прочтения статей.
РЕЗЮМЕ
Подводя итог, я думаю, что анализ чувствительности можно очень легко провести с помощью Amazon Comprehend. Я проверил его на двух статьях и обнаружил, что большинство результатов, которые я получил, действительны и абсолютно соответствуют истинному содержанию обзоров. Однако с точки зрения управления ожиданиями важно подчеркнуть, что он не будет идеальным в каждом случае, и, вероятно, результат чувствителен к длине текста. Тем не менее, это может быть очень полезно, особенно когда вам нужно оценить огромное количество длинных текстов. Описанный выше метод можно обобщить, а это означает, что несколько отзывов могут быть проанализированы аналогичным образом одновременно, чтобы получить более сложную и полную картину конкретного продукта. Это может быть очень полезно, если мы находимся в ситуации покупки или если мы работаем в компании и хотим собрать и оценить отзывы о наших продуктах.